“EPFL” data set: Multi-camera Pedestrian Videos

results, please cite one of the references below.
On this page you can download a few multi-camera sequences that we acquired for developing and testing our people detection and tracking framework. All of the sequences feature several synchronised video streams filming the same area under different angles. All cameras are located about 2 meters from the ground. All pedestrians on the sequences are members of our laboratory, so there is no privacy issue. For the Basketball sequence, we received consent from the team.
For every video sequence available on this page, we provide with the camera calibration information. Depending on the sequence, this can be in the form of two homographies per cameras, mapping respectively the ground plane and the head plane, that is the plane parallel to the ground plane and located at head height. For other sequences, we provide the camera calibration for the Tsai model or in the generic projective camera format. More detail about calibration is given below. For some of the sequences, we also provide our manually annotated ground truth, which allows to benchmark detection and tracking results. More information on using those files is also provided below.
Note that a GPL version of our people detection algorithm is available on the software page of this web site.
All videos, calibration and ground truth files available on this page are copyrighted by CVLab – EPFL. You can use them for research purposes. If you use them to publish
Laboratory sequences
These sequences were shot inside our laboratory by 4 cameras. Four (respectively six) people are sequentially entering the room and walking around for 2 1/2 minutes. The frame rate is 25 fps and the videos are encoded using MPEG-4 codec.
 |
 |
 |
 |
| [Camera 0] | [Camera 1] | [Camera 2] | [Camera 3] |
Calibration file for the 4 people indoor sequence.
 |
 |
 |
 |
| [Camera 0] | [Camera 1] | [Camera 2] | [Camera 3] |
Calibration file for the 6 people indoor sequence.
Campus sequences
These two sequences called campus were shot outside on our campus with 3 DV cameras. Up to four people are simultaneously walking in front of them. The white line on the screenshots shows the limits of the area that we defined to obtain our tracking results. The frame rate is 25 fps and the videos are encoded using Indeo 5 codec.
 |
 |
 |
| [Seq.1, cam. 0] | [Seq.1, cam. 1] | [Seq.1, cam. 2] |
| [Seq.2, cam. 0] | [Seq.2, cam. 1] | [Seq.2, cam. 2] |
Calibration file for the two above outdoor scenes.
Terrace sequences
The sequences below, called terrace, were shot outside our building on a terrace. Up to 7 people evolve in front of 4 DV cameras, for around 3 1/2 minutes. The frame rate is 25 fps and the videos are encoded using Indeo 5 codec.
 |
 |
 |
 |
| [Seq.1, cam. 0] | [Seq.1, cam. 1] | [Seq.1, cam. 2] | [Seq.1, cam. 3] |
| [Seq.2, cam. 0] | [Seq.2, cam. 1] | [Seq.2, cam. 2] | [Seq.1, cam. 3] |
Calibration file for the terrace scene.
Passageway sequence
This sequence dubbed passageway was filmed in an underground passageway to a train station. It was acquired with 4 DV cameras at 25 fps, and is encoded with Indeo 5. It is a rather difficult sequence due to the poor lighting.
 |
 |
 |
 |
| [Seq.1, cam. 0] | [Seq.1, cam. 1] | [Seq.1, cam. 2] | [Seq.1, cam. 3] |
Calibration file for the passageway scene.
Basketball sequence
This sequence was filmed at a training session of a local basketball team. It was acquired with 4 DV cameras at 25 fps, and is encoded with Indeo 5.
|
 |
 |
 |
| [Seq.1, cam. 0] | [Seq.1, cam. 1] | [Seq.1, cam. 2] | [Seq.1, cam. 3] |
Calibration file for the basketball scene.
Camera calibration
POM only needs a simple calibration consisting of two homographies per camera view, which project the ground plane in top view to the ground plane in camera views and to the head plane in camera views (a plane parallel to the ground plane but located 1.75 m higher). Therefore, the calibration files given above consist of 2 homographies per camera. In degenerate cases where the camera is located inside the head plane, this one will project to a horizontal line in the camera image. When this happens, we do not provide a homography for the head plane, but instead we give the height of the line in which the head plane will project. This is expressed in percentage of the image height, starting from the top.
The homographies given in the calibration files project points in the camera views to their corresponding location on the top view of the ground plane, that is
H * X_image = X_topview .
We have also computed the camera calibration using the Tsai calibration toolkit for some of our sequences. We also make them available for download. They consist of an XML file per camera view, containing the standard Tsai calibration parameters. Note that the image size used for calibration might differ from the size of the video sequences. In this case, the image coordinates obtained with the calibration should be normalized to the size of the video.
Ground truth
We have created a ground truth data for some of the video sequences presented above, by locating and identifying the people in some frames at a regular interval.
To use these ground truth files, you must rely on the same calibration with the exact same parameters that we used when generating the data. We call top view the rectangular area of the ground plane in which we perform tracking.
This area is of dimensions tv_width x tv_height and has top left coordinate (tv_origin_x, tv_origin_y). Besides, we call grid our discretization of the top view area into grid_width x grid_height cells. An example is illustrated by the figure below, in which the grid has dimensions 5 x 4.
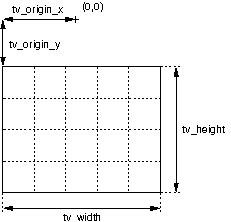
The people’s position in the ground truth are expressed in discrete grid coordinates. In order to be projected into the images with homographies or the Tsai calibration, these grid coordinates need to be translated into top view coordinates. We provide below a simple C function that performs this translation. This function takes the following parameters:
- pos : the person position coming from the ground truth file
- grid_width, grid_height : the grid dimension
- tv_origin_x, tv_origin_y : the top left corner of the top view
- tv_width, tv_height : the top view dimension
- tv_x, tv_y : the top view coordinates, i.e. the output of the function
void grid_to_tv(int pos, int grid_width, int grid_height, float tv_origin_x, float tv_origin_y, float tv_width, float tv_height, float &tv_x, float &tv_y) { tv_x = ( (pos % grid_width) + 0.5 ) * (tv_width / grid_width) + tv_origin_x; tv_y = ( (pos / grid_width) + 0.5 ) * (tv_height / grid_height) + tv_origin_y; }
The table below summarizes the aforementionned parameters for the ground truth files we provide. Note that the ground truth for the terrace sequence has been generated with the Tsai calibration provided in the table. You will need to use this one to get a proper bounding box alignment.
| Ground Truth | Grid dimensions | Top view origin | Top view dimensions | Calibration |
|---|---|---|---|---|
| 6-people laboratory | 56 x 56 | (0 , 0) | 358 x 360 | file |
| terrace, seq. 1 | 30 x 44 | (-500 , -1,500) | 7,500 x 11,000 | file (Tsai) |
| passageway, seq. 1 | 40 x 99 | (0 , 38.48) | 155 x 381 | file |
The format of the ground truth file is the following:
1 <number of frames> <number of people> <grid width> <grid height> <step size> <first frame> <last frame> <pos> <pos> <pos> ... <pos> <pos> <pos> ... . . .
where <number of frames> is the total number of frames, <number of people> is the number of people for which we have produced a ground truth, <grid width> and <grid height> are the ground plane grid dimensions, <step size> is the frame interval between two ground truth labels (i.e. if set to 25, then there is a label once every 25 frames), and <first frame> and <last frame> are the first and last frames for which a label has been entered.
After the header, every line represents the positions of people at a given frame. <pos> is the position of a person in the grid. It is normally a integer >= 0, but can be -1 if undefined (i.e. no label has been produced for this frame) or -2 if the person is currently out of the grid.
Third-Partie annotations
Third partie annotations, with different modalities are available.
https://bitbucket.org/merayxu/multiview-object-tracking-dataset
References
Multi-Camera People Tracking with a Probabilistic Occupancy Map
IEEE Transactions on Pattern Analysis and Machine Intelligence. 2008. Vol. 30, num. 2, p. 267-282. DOI : 10.1109/TPAMI.2007.1174.Contact
| Pierre Baqué (primary contact) | [URL] | [e-mail] |
| Pascal Fua | [URL] | [e-mail] |